
This is the first post of a series about developing type-1 hypervisors, also known as native or bare-metal hypervisors. It introduces to Intel’s VMX technology, describes interactions between a virtual machine and a hypervisor as well as gives some insight on the control structures required. This post should give some theoretical knowledge base required for the next ones, in which we will implement a basic hypervisor using Bareflank. It assumes that you have some knowledge about IA-32 architecture. There will be more than 5 terms actually, but the most important are those in headers. The following posts will assume that the reader knows what they are for and what is their scope.
Introduction to VMX
Virtual-machine extensions (VMX) define processor-level support for virtual machines on IA-32 and IA-32e processors. There are two kinds of VMX operation: VMX root operation and VMX non-root operation.
CPU in VMX root operation is almost identical to that of non-VMX operation, except for some additional instructions (for setting up and starting virtual machines) and some CR limitations (e.g. paging has to be enabled at all times, meaning that switching between processor modes is limited).
In VMX non-root operation CPU behaviour is limited or altered. Some operations and events are forbidden, others can be configured to interrupt normal program flow and exit to a special handler running in root operation. This behaviour cannot be altered from within non-root operation mode even in ring 0, that is why VMX root mode is often called ring -1.
In later versions of VMX, there are new instructions available (VMCALL and VMFUNC). This allows for easier implementation of hypercalls, where a virtualization-aware OS or application wants to exchange information directly with a hypervisor. Hypercalls can be used for managing a virtual environment or to get some statistics from hypervisor - useful for debugging. Without these instructions, it is still possible to implement similar functionality, as we will see later in the series.
Hypervisors can be classified as one of two types:
- type-1 (bare-metal, native) hypervisors. A hypervisor is run directly on the hardware and is not managed by an operating system. Examples of this type are Xen, Hyper-V and Oracle VM Server. The first hypervisors, developed by IBM in the 1960s, were also of this type.
- type-2 (hosted) hypervisors. In this case, each virtual machine, as well as the hypervisor itself, are just other processes running on top of the operating system. Examples are VMware Workstation, VMware Player, VirtualBox and QEMU.
Note that there is no clear distinction between those two, there are some hypervisors that are somewhere in between. KVM for example is a kernel module that converts a whole OS to a type-1 hypervisor, but because Linux still is an operating system it has to control access to resources between processes, as type-2 hypervisor does.
VMM
Virtual machine monitor. It is a part of the software that handles all VM exits. Works in VMX root operation, it has full access to the hardware and almost full control of CPU. Why almost? It has some of the bits in control registers fixed to ensure proper execution. Trying to change CPU mode is one of the examples of such restrictions, so goodbye, real mode. Another thing that is limited in VMX root operation is that INIT signal is blocked - because of that it is impossible to reset other cores of CPU, which would effectively destroy everything that VMX gave.
Other than those limitations, VMM can use everything that IA-32 has to offer. This includes interrupt and exception handlers (very useful, especially when passing instructions from VM to real hardware), virtual memory (might be used for easier mapping of VM memory, but it isn’t common) and even going to ring 3 (I don’t think anyone would like to lower his/her privilege level here, but who knows?).
It is VMM’s task to isolate VMs from each other, if desired. VMM is the place where code and data for handlers is located, because of that it is crucial that VMM’s memory is inaccessible from virtual machines. Such protection is possible with the help of EPT (extended page-table), but this mechanism is worthy of another post so I won’t describe it further right now.
Intel’s Software Developer’s Manual calls this host, while most of the world
leave this name for something else - I’ll mention it later in this post. As with
other multi-processor environments, we can develop symmetric and asymmetric
VMMs. In this series, I will assume that a VMM on one core is a separate entity
from another core, even on symmetrical systems. Hopefully, this will better show
all nuances and possibilities of virtualization.
A hypervisor is more than only its VMM part. It needs some initial setup, most likely a glue layer for the underlying system and sometimes checks for its starting arguments.
VM
Virtual machine, also called guest software. It consists of OS and application software. Software running on VM usually is not aware of the fact that VMM controls hardware and that there may be other VMs running on the same platform, but it can be. Most of the times any application that can run on real hardware can also run inside a VM, depending on hypervisor implementation.
As with VMM, VMs can also be symmetrical or asymmetrical when it comes to multi-processor execution. Again, I will restrict VM to one core. Here it makes even more sense because VMM can implement a scheduler and run multiple VMs on one physical core, in turn. For most people that were using only type-2 hypervisors one VM probably means one HDD, couple GBs of RAM and a multicore CPU, as it meant to me not so long ago. So, let’s call one virtual PC a virtual environment and everything seen by one core (general purpose registers, MSRs, APIC, memory etc.) is a virtual machine. This definition of VM is more or less consistent with how they are managed under the hood. I’ll try to stick to these names, but bear with me if I make a mistake at some point :)
All VMs work in VMX non-root operation, they are called guest in SDM as well
as by everyone else, but…
Host-VM
There is one special VM that was created as first VM, it is a virtualized version of the operating system or firmware that hypervisor was started with. Note that it is sometimes called as a host (because it was there before hypervisor) and sometimes as a guest (because it is a VM after all), depending on context.
Handlers for this VM, with few exceptions, pass through all accesses to the hardware in order to make continued operation of the OS/FW possible.
In theory, this VM isn’t necessary, but it is convenient to leave it. Host-VM provides many useful parts, such as memory management, ACPI tables, firmware for peripheral devices etc. Hypervisor would have to do all that and much more by itself if it wasn’t for this VM.
Transitions
There are only two types of transition: VM exit and VM entry. As you can see, they are named relative to the VM, as this is where the CPU should spend most of the time. VM exit is a transition from VM to VMM, or non-root to root operation (these are synonymous); VM entry - the other way around.
Multiple checks are performed both on entries and exits. When an error occurred during VM entry it is possible to just not get into VM or return as soon as error on VM side happens. Error on VM exit is worse - they happen only when there is no valid VMM to get back to, which leads to VMX abort, after which the processor is put into a shutdown state.
Old state is saved and a new one is loaded from VMCS (virtual machine control structure, described later) or structures that VMCS points to. There is a field for MSRs table, so VMM can fill in the ones that it intends to change and they will be saved/restored as a part of the transition.
VM entries
VM entries happen as a result of VMLAUNCH or VMRESUME. Steps are done in order:
- Basic checks are performed to ensure that VM entry can commence (valid VMM state, valid VMCS).
- The control and host-state areas of the VMCS are checked to ensure that they are proper for supporting VMX non-root operation and that the VMCS is correctly configured to support the next VM exit.
- The guest-state area of the VMCS is checked to ensure that, after the VM entry completes, the state of the logical processor is legal.
- MSRs are loaded from the VM-entry MSR-load area.
- If VMLAUNCH is being executed, the launch state of the VMCS is set to “launched”.
- An event may be injected in the guest context.
VM exits
There are many possible reasons for the VM exit.
- Information about the cause of the VM exit is recorded in the VM-exit information fields and VM-entry control fields are modified.
- Processor state is saved in the guest-state area.
- MSRs may be saved in the VM-exit MSR-store area.
- Processor state is loaded based in part on the host-state area and some VM-exit controls. Address-range monitoring is cleared.
- MSRs may be loaded from the VM-exit MSR-load area.
As you can see, there is no explicit error checking performed - it doesn’t make sense to return back to VM anyway in this case. An error can happen when for any reason VMCS gets corrupted (memory range containing VMCS was not properly protected from VMs, different core in VMM mode or another hardware through DMA corrupted VMCS, physical memory error). It isn’t possible to return to a non-VMX state because it is not saved anywhere - host-VM is still only a VM, it is indistinguishable from any other VM at this time. CPU is put into a shutdown state and only RESET signal can bring it back. All this is done to prevent any chance of privilege elevation - safety is considered more important than continued operation in this case.
VMCS
VM control structure. It is pointed to by VMCS pointer - one per logical processor, which is the main reason why VMs are limited to one core from the developer’s point of view. There is always one VMCS per VM, even on symmetric implementations, because some of its fields describe CPU state at the time of the transition between VM and VMM so they cannot be shared by multiple cores.
The exact layout of this structure, as well as its size, is implementation specific. For this reason, as well as because it can be internally cached by CPU for better performance, fields of VMCS should not be accessed directly. Special instructions defined by VMX should be used instead (VMCLEAR, VMREAD and VMWRITE).
The VMCS data is organized into six logical groups:
- Guest-state area - processor state is saved into the guest-state area on VM exits and loaded from there on VM entries.
- Host-state area - processor state is loaded from the host-state area on VM exits. It is usually saved only once when creating VMCS.
- VM-execution control fields - these fields control processor behaviour in VMX non-root operation. They determine in part the causes of VM exits.
- VM-exit control fields - these fields control VM exits.
- VM-entry control fields - these fields control VM entries.
- VM-exit information fields - these fields receive information on VM exits and describe the cause and the nature of VM exits. On some processors, these fields are read-only.
The VM-execution control fields, the VM-exit control fields, and the VM-entry control fields are sometimes referred to collectively as VMX controls.
An overview of fields available in VMCS is available here. Note that not all of those fields are available on all processors, also new ones can be added in the future.
VMCS can be in one of six launch states, depending mostly on the last VMCS-related instruction called:
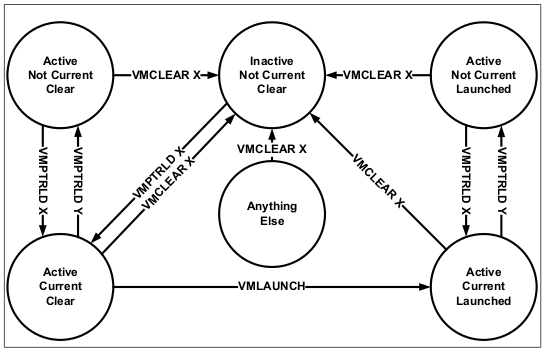
VM can migrate between cores; in this case, VMCS can be reused on another core, but only after it was brought out of launched state and flushed to memory. VMCLEAR instruction does exactly that. Despite its name, it does not clear any fields, except for changing VMCS’s state, but this field isn’t accessible anyway.
Size of VMCS is limited to 4 kB, but it can have pointers to other structures. These pointers contain physical addresses because some of them are needed before CR3 can be loaded. All of that memory should remain hidden from VMs.
Summary
I hope that this post described what VMM and VM is from developers (and hardware) point of view. VM entry and VM exit are closely related to VMCS, it’s difficult to explain them separately. All important fields of VMCS will be described at the time when they will be used.
Next post will show how to build Bareflank without any special treatment of VM exits. We will also start OS from it and show that it is still usable, and what is different than it was on real hardware.
If you think we can help in improving the security of your firmware or you are
looking for someone who can boot your product by leveraging advanced features of
used hardware platform, feel free to book a call with
us or
drop us email to contact<at>3mdeb<dot>com. And if you want to stay up-to-date
on all things firmware security and optimization, be sure to sign up for our
newsletter:
