
In this post I want to share some findings about ECC on PC Engines apu platforms. I’ll try to shortly describe what ECC is, why is it so desired, what problems with enabling this feature were encountered and how to test whether ECC works or not using MemTest86.
Introduction
Sometimes a bit in RAM changes its value spontaneously due to electrical or magnetic interference. It can be caused by background radiation, cosmic rays or recently attacks using row hammering. Error-correcting code (ECC) memory helps with mitigation of this problem by adding more data storage for storing information that makes detection and correction of errors possible. Memory controller scans whole ECC enabled memory, reading every piece of data, checking (and correcting if necessary) for errors and writing data back to memory. This process is called memory scrubbing. As ECC can correct only limited number of flipped bits scrubbing has to be done periodically, before multiple errors within one ECC word can occur - time between scrubs isn’t fixed, and according to BKDG, 52740 Rev 3.06:
There are many factors which influence scrub rates. Among these are:
- The size of memory or cache to be scrubbed
- Resistance to upsets
- Geographic location and altitude
- Alpha particle contribution of packaging
- Performance sensitivity
- Risk aversion
Usually, ECC can fix only single bit, and detect two changed bits in ECC word,
but with AMD Embedded G series GX-412TC SoC included in PC Engines apu2 platform
a variation named x4 ECC is used:
The x4 code uses thirty-six 4-bit symbols to make a 144-bit ECC word made up of 128 data bits and 16 check bits. The x4 code is a single symbol correcting (SSC) and a double symbol detecting (DSD) code. This means the x4 code is able to correct 100% of single symbol errors (any bit error combination within one symbol), and detect 100% of double symbol errors (any bit error combination within two symbols).
ECC feature requires support from the memory controller (on SoC), memory banks, connections between them on a motherboard (memory bus is wider to support reading check bits at the same time as main data) and firmware which sets everything up. Further operation is transparent to operating systems, but it is possible for them to gather information about how often errors are being corrected.
It is possible to turn off ECC check and error reporting for one range of memory. This range is used as a framebuffer for integrated GPU - scrubbing could have an impact on framerate and things like V-sync, and one changed pixel visible only for a fraction of second is acceptable.
Testing for ECC support
To be sure that ECC works one must notice a corrected ECC error. There are few problems to this:
- ECC has to be available and properly configured
- ECC error reporting must be enabled
- there must be a correctable ECC error
First two points are something that can and has to be done in firmware as long as a hardware is compatible, so enabling it takes some work and a whole lot of research, but is definitely possible.
The last issue is actually the hardest one. It is impossible to reliably simulate e.g. a cosmic ray, and row hammering takes a lot of time and requires specific knowledge of the internal structure of a memory bank. To help with testing vendors of memory controllers (and SoCs) provide ways of introducing an error for test and debug purposes. This feature enables tools like MemTest86 to inject ECC errors when running tests - keep in mind that ECC injection is available only in paid versions of MemTest86 run from UEFI (so coreboot built with tianocore payload was used for testing in my research) and needs to be enabled either from the menu or in the configuration file. The most important settings in this file are:
|
|
Running this test on unmodified coreboot resulted in something like the following lines in log file:
|
|
As you can see, MemTest86 injects ECC errors (or at least tries to) in lines
starting with inject_amd64, but these errors are not reported - according to
MemTest86 troubleshooting page
a line with either memory address or the DRAM rank/bank/row/column should be
printed here, as well as in the generated report, as shown in
this sample. This
means that something is wrong. There is a lot of relevant debug information
included, but names differ slightly between log and register names in BKDG. More
information about reported values and their impact on the issue will be revealed
in the next sections.
Issues with ECC enabling
According to previous work on this issue, ECC error injection fails due to a range of memory that is used by APUs integrated graphics being excluded from ECC support, which means that it is impossible to test in a reliable way whether ECC works. This feature is controlled by a couple of registers, one of them is D18F5x240, which has bit EccExclEn (see page 496 of BKDG). This bit is set by AGESA as 1 soon after memory training and excluded range is incorrectly set as a whole memory for systems without integrated graphics.
As AGESA is included as a binary blob it can’t be fixed in its code and some workarounds were needed.
Potential workarounds
AGESA specification mentions a build time option:
BLDCFG_UMA_ALLOCATION_MODE Supply the UMA memory allocation mode build time customization, if any. The default mode is Auto.
- UMA_NONE — no UMA memory will be allocated.
- UMA_SPECIFIED — up to the requested UMA memory will be allocated.
- UMA_AUTO — allocate the optimum UMA memory size for the platform.
For APUs with integrated graphics, this will provide the optimum UMA allocation for the platform and for other platforms will be the same as NONE
There is also a runtime option UmaMode in MemConfig, which is a parameter
for AmdInitPost, but it isn’t clear if AGESA uses data received from host or
changes it along the way before memory initialization. However, the initial
value of UmaMode already is UMA_NONE, and neither changing it before calling
AmdInitPost nor in any callout functions doesn’t change the outcome.
Clearing bit EccExclEn in register D18F5x240 from coreboot after it gets set by AGESA seemed to work on a tested platform (apu2). Description of this register in BKDG informs that
BIOS must quiesce all other forms of DRAM traffic when configuring this range. See MSRC001_001F[DisDramScrub].
Although it did work without disabling scrubbing (perhaps because of all memory was excluded from ECC anyway) we followed the process described in BKDG just to be safe.
Additional required fixes
Somewhere between memory training and setting UMA I receive
WARNING Event: 04012200 Data: 0, 0, 0, 0. According to AGESA specification
04012200 corresponds to:
MEM_WARNING_BANK_INTERLEAVING_NOT_ENABLED
I don’t know if this is connected in any way to problems with ECC enabling.
Later test on different platforms gave some additional findings. Implemented fix did work on apu2 and apu4, but not on apu3 or apu5. Luckily MemTest86 leaves enough data to find out what’s wrong, it was only a question of interpreting log files. First, part of log from apu4 where this fix worked:
|
|
Lines marked with -> are the ones that differ from the previous log.
MCA NB Status High corresponds to D18F3x4C MCA NB Status High in BKDG, which
is an alias of MSR0000_0411 MC4 Machine Check Status. You can find more info
about this register there, but basically, when the most significant bit (Val) is
set, a valid error has been detected, so we’re good. The bottom lines report
status (full 64 bits this time, again, refer to BKDG for full description) and
address of injected error, as well as a more human-friendly error message, that
would also be visible on screen and in the generated report. Note that reported
error count is still 0, as this error was detected and corrected by hardware
before any read operation (by MemTest86, OS or any other application) on this
address was performed.
This is output from apu5, where forementioned fix didn’t work, with important
lines marked with ->:
|
|
As you can see, none of injection attempts succeeded so reported value of
MCA NB Status High was 00000000. Also value of nb_arr_add (aka
D18F3xB8 NB Array Address in BKDG) differs, so next logical step was clearing
this register’s value in coreboot as well. After doing so ECC errors were
reported:
|
|
Summary and additional findings
After the last fix, ECC is enabled as well as ECC error injection on all supported hardware (that is, every apu platform with 4 GB of memory). Generated reports should look like this:
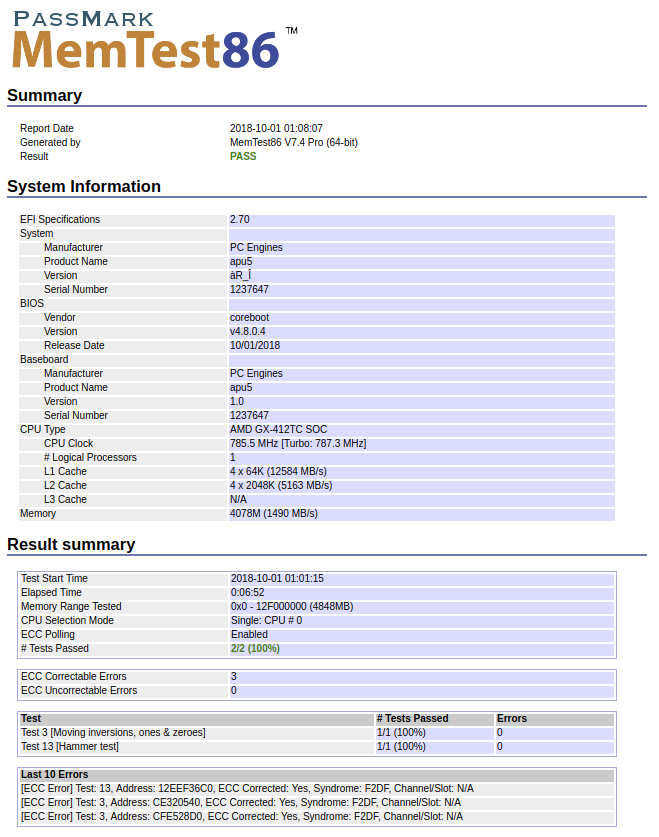
Every corrected ECC error has the same syndrome - F2DF. It is caused by
MemTest86 setting D18F3xBC_x8 (DRAM ECC) to 0012000F. More info about the
meaning of these is available in
BKDG
on pages 172-174 (ECC syndromes) and 456 (DRAM ECC register, NB Array Address).
Another thing is that sometimes more than one ECC error for a test is injected. It is caused by internal work of injection - only bits inside a cache line can be chosen, but an error is injected on next non-cached operation at accessed address, which can change or not between any of three attempts to inject an error.
Changes in code can be found here, we’re also planning to push it upstream soon. We would also think about adding an option to disable ECC injection if the community decides that it is needed, as even some of the MemTest86 developers believe that injection should be enabled for debug purposes only.
