
Nowadays, application of programming in assembly language is very small. Writing production code in assembly may be found in the most demanding tasks in embedded. Even in modern firmware (coreboot, EDK2) most of the code is written in C. Honesly, that’s quite undestandable, assembly code isn’t easy to read nor write and some state that it’s no longer needed to be known. In my opinion, that’s far from the truth.
Not only it’s heavily used in reverse engineering, very important especially in software/firmware security, its design impact more or less code in virtually any programming language. Let’s set an example. Consider those two lines of C code:
|
|
Even C’s syntax (considered low-level nowadays) create an impression that they
are more or less the same, except that buffer is const char* and buffer2
is char* and the range: buffer is freed automatically at the and of current
block. However, someone with some knowledge of internls know that first line has
virtually no overhead (because all local variables may be allocated and freed at
the same time, it takes 2 instructions), while second one involves kernel
activity to map needed space, needs to update heap structures, etc. Except that
malloc() often happen to introduce memory leaks, on the other hand, the first
method may cause stack overflow in some cases.
This is just one of many examples where low-level details (assembly, network stack, devices, etc.) condition higher level code execution. That’s why every senior software developer should know them and, of course, every security specialist. Except that, it’s essentional to anyone interested in Reverse Enineering.
This article is meant to preasent the most important ideas behind x86 assembly just to show how does it work and what are its limitations. If you want to code in assembly or read disassembly, I recommend to look at [x86 instruction set] (https://c9x.me/x86/) and tutorials like this. If you are interested in advanced optimization you’d have to dive into CPU model specific documentation.
Basics of x86 CPU
We have CPU — computation unit and RAM for temporary data storage. We are usually separated from all other devices but we use OS interface, which reuses concepts we use for those two. Generally speaking, everything that happens in a computer is series of passing data between components and transforming them in between.
For example, when we display a web page we can think of it:
- we have given an address in memory.
- transform it into request conforming standard.
- pass a request to the networking device
- accept response
- transform text into an image
- pass the image to the graphic card
The job of application is just to transform the data and inform OS where is the product, what it is and where to pass it. RAM is a medium for that exchange as well as storage for middle products. RAM also store instructions how to perform those transformations. Assembly language is a textual representation of codes understood by CPU.
Memory
We can think of RAM as a function. Every byte in memory has its ordinal number. We use it to read or change its value. Bytes are usually accessed in groups of 4(32bit) or 8(64-bit).
X86 CPU never uses two memory locations at the same time. That’s why it has own memory called registers. In modern x86 architecture, there are 16 64-bit general purpose registers called: RAX, RBX, RCX, RDX, RDI (destination index), RSI (source index), RBP (base pointer), RSP (stack pointer), R8-R15. Despite meaningful names of some, only RSP preserved special meaning. This naming was important when it was usual to code directly in assembly). “R” letter in beginning denote its 64-bits as during 40 years of x86 evolution registers have grown from 16-bit (AX, BX, etc), to 32-bit (EAX, EBX, etc). Among special registers, we have RIP (instruction pointer) stores pointer (ordinal number in memory) of the next instruction to run and EFLAGS which register special situations (like zeroing register or overflow while adding). Those special registers are never accessed directly.
To move data between registers and memory we use MOV instruction. Example:
|
|
which loads constant value 0xff to RAX register. This form of assembly language is called AT&T and mainly widespread in GNU world. Other popular is Intel Syntax. The most important difference is argument order and lack of sigils:
|
|
In this document, I use AT&T syntax. Other variants are:
|
|
Note that labels in the machine code are just constants. Labels are for programmers convenience. Remembering addresses for every little thing would be hard, but it’s not the only reason. In modern OS controlled code must not access any address without OSs permission. Labels mark places allocated at program loading. It has initial value:
|
|
For pointer loading, there is other set instruction: LEA (Load Effective
Address):
|
|
Transformations
There are many instructions for data transformations. Among the most popular:
|
|
There are many more of them, but most common of them follow the same pattern. That’s why it’s quite easy to automatically trace value changes. Some instructions have implicit parameters, however still, we need just encode exception. Example:
|
|
RDX:RAX means 128-bit value with higher 64-bits in RDX and other in RAX.
Such a solution let us never lose data due to overflow. On the other hand, cause
a pitfall of DIV instruction — if the operand is not enough to make result
64-bit or operand is 0 — CPU exception is issued (mentioned later).
There are also special instructions and registers for floating point arithmetic, for matrix operations, and some reserved ones only for OS/firmware code, among others to communicate with other devices. And configure protection mechanisms.
Jumps
Of course, we can execute an instruction not in an order using jumps.
|
|
Most of the jumps are relative to current RIP position. Thanks to this OS can load our program at any point in memory. Similarly, once compiled function can be placed at any point of program binary.
|
|
will disassemble as:
|
|
Disassembly shows whole address, but when we look at the machine codes, jump takes only two bytes so it can’t be absolute address. 0xEB encodes relative jump and another byte is 8-bit signed offset coded so that highest bit means -0x81 instead of 0x80 so 0xfa = -0x80 + 0x8a = -0x06, which is length of both instructions.
Conditionals
We can also make conditional jumps. EFLAGS register is used for that. For
example, if we call
|
|
except for subtracting RAX, specific bit of EFLAGS will be set to 1 if %rax
will become 0 (ie. was 5 in the first place) and other if it becomes negative.
There are instructions that make jump according to EFLAGS bits and special
CMP instruction which sets EFLAGS like SUB but doesn’t store the result.
Similarly, TEST does AND without storing the result (usually used for bit
fields).
|
|
Note that, it’s totally valid to put many conditional jumps one by one, because
they don’t affect EFLAGS register.
Stack
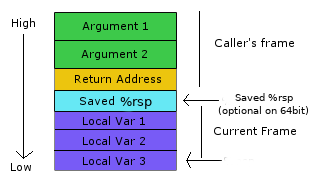 graphic from
here
graphic from
here
For very temporary storage of values, there is special memory range that
implements stack structure. RSP register points at last pushed value. There
are two special instructions for that:
|
|
There is no popping in memory. Of course, they are faster and smaller than add/sub + mov combination. As you can see, the stack is growing backwards. There is no standard way to determine boundaries for the stack.
As RSP is general purpose register, there’s nothing wrong with using it in normal operations. In fact, it’s how local variables are compiled in C (unless they are in register).
|
|
BTW. stack overflow is a kind of attack that exploits stack so that stack overlaps with other variable. Originally it could overwrite code too, but modern OSs prevent writing code section and executing data section. Note that on 32-bit OSs stack cells are only 4-bytes long.
Calls
For calling functions there are 2 other commands:
|
|
CALL works just like JMP, but pushes RIP first. At the end of the function
we put RET which simply pops that value back, so that execution continues
after last CALL. Of course, if you don’t change RSP value to the initial
value, RET takes (%rsp) anyway, so in most cases, it would cause a crash.
The stack is also used to pass function parameters. In 32-bit architecture all
of them are put on the stack (the first argument pushed as last). Depending on
convention caller al callee was responsible for freeing parameters. That’s why
there is such variant of RET with a parameter which indicates how much would
be added to RSP after popping to RIP.
The original purpose of EBP was to store ESP value before allocating local
variables. So that you can allocate variables in the middle of function not
caring how much because you would use EBP, that’s why Base Pointer. In the
end, you would just reset ESP to RBP before RET. There were (and still
are) instructions for that: ENTER and LEAVE. However as those are clearly
coding oriented features it’s no longer convention in 64-bit architecture, but
still may be found. For instance, gcc without optimization still does it:
|
|
The reason why I grep out lines starting with a dot is additional directives which are information for compiler rather than actual instructions. ‘l’ and ‘q’ at the end of instructions marks operand size. It is required only one constant->mem write is performed (because there’s no way to deduce it).
In 64-bit architecture convention changed a little because first 5 parameters
(except structures bigger than 8 bytes) are passed through registers: RDI,
RSI, RDX, RCX, R8 and R9. As you can see on above code, the return
value is put into %rax register (unless it’s too big), but as the main return
32-bit value, EAX register is actually used.
RBX, RBP, and R12-R15 are considered callee-save, which means, that all functions should provide that their values will be the same after returning.
Interrupts and syscalls
Very similar thing are interrupts — they are also kind of functions implemented
by OS or boot firmware, but they are usually called by hardware. When CPU get
such interrupt, normal execution is stopped and restored when the interrupt is
handled. Also, CPU itself can generate the interrupt, that’s how CPU exceptions
work (they are issued when some illegal instruction is called). There is also
INT instruction to generate the interrupt.
For a long time, this feature was used to provide runtime services in BIOS and
DOS. In *nix 32-bit OSs (Linux,*BSD) it’s still used: int 0x80. EAX (or it’s
part) was typically specifying system function and other registers contained
parameters. In 64-bit architecture, there is syscall instruction instead,
which works very similar. For example for read() function:
|
|
However, those calls are usually called using C wrapper calls so the most likely place to find them are shared libraries.
Conclusion
This brief explanation is probably not enough to code in assembly language but
will let you understand most of the disassembly of userspace programs. As modern
programs make much use of shared libraries, those calls used most of the time.
The good thing is that unless you deal with OS/firmware calls you don’t need to
care about multitasking, caching etc. You will probably face strange constructs
like call (%rip), which doesn’t any make functional sense but turns out to
help CPU execute code faster. Another good news is that userspace program is
written as though it was only processed running on the machine which simplifies
it a lot.
Anyway this should give you a good start to understand most of assembly code (assuming that you use instruction reference). If you deal with obfuscated code, you will proabably need some help from dedicated software like IDA.
We are open to help you if some of presented information is unclear or you are interested in more detail. Please let us know.
