
Probably there was never a programming language that would fascinate me as much as assembly. In fact, it was my second “real language” (after Pascal/Delphi and DOS batch) and the first one I would really understand. Of course, the internals of protected mode initialization was too much for 15-year-old and I finally moved to C and *nix shell. Anyway, I always liked the feeling that I know what I’m really doing but more complex languages are needed nowadays.
Having tried almost any popular language out there I enjoy getting to very foundations of software and working with disassembly every now and then. Reverse engineering and low level debugging are pretty obvious applications for disassembly, but having worked with it a little bit more I came to the conclusion that power of working on that level is much more.
What can we get?
I’ve noticed that with good knowledge of environment we are working with and right tools assembly code might be much handier than getting through spaghetti code. There are two reasons for that.
The first reason is that when we’ve got binary, we’ve got everything explicitly specified inconsistent address space. While working with multi-platform code (like coreboot, Linux kernel or EDK2) it’s sometimes hard to tell which implementation of the same function would be actually used, because it’s decided inbuilt system, based on distributed configuration. In disassembly, we usually have only code actually used and every reference is quite clear.
Of course, in most cases, we have some sort of external code — dynamic libraries, system calls, UEFI services. They are external for a reason though. Also, their meaning is clearly specified so we may treat those calls as the black box. Another time we may use it to reason where data come in and out.
The second reason is that assembly language is very simple. That’s why it’s very hard to code in, but also very easy to interpret automatically. One line per instruction. Most of the instructions follow the same pattern — one operand read-only, the other is modified according to it. It took me some 350 LOC in AWK to take disassembly and tell for a jumpless piece of code how data in registers and memory changes. Where possible, actual values appear, where value depends on initial value, the complete transformation is recorded. Of course, it’s only prototype and more advanced instructions are not yet supported, but it’s already promising. With proper jump support, we could reduce multiple control switches into a minimal set of transformations for given goal, even separate it from the rest of code. However far it would go, doing a similar thing with higher level language seems many times more complex.
For fuller and more reliable and efficient implementation
Capstone-Keystone-Unicorn tools could be used. We may also consider QEMU (which
allows us to dump all ongoing operations and changing state) and GDB
integration. When something simpler is needed we may consider mprotect() Linux
call for runtime code rebuilding and analysis. Recently I have found another
very interesting project:
The Witchcraft Compiler Collection.
Before you continue, you should know very basics of x86 assembly language, which you can find in [another blog post](TODO:address here).
Binary organization
Machine code is usually packed in some sort of file type. In old times COM
files used to contained raw machine code and the only assumption was that the
code would be placed at 0x100. However, nowadays we use more sophisticated
formats because modern CPUs offer access rights for memory regions so that we
can disable write access for code and constants and execution for data regions.
Another reason is that often we want to load shared libraries — the code that
can be shared between processes. Of course, it’s possible to load them using
dedicated system calls, but it’s much more convenient to let executable loader
do it for us. Except that, we want to attach debugging symbols for convenient
execution analysis. Moreover, modern executable formats contain information
about target architecture, checksums and other information about the code.
Except that, producing binaries directly from source code would be very impractical and inefficient for big projects. That’s why in modern systems we have at least 4 file types for code:
- Object files — usually generated per module, containing functions with their data. At this point, no function dependencies are checked so that we may take care of later. Thanks to this we can separate compilation process from resolving dependencies. Extension *.o in *nix and *.obj in Windows.
- Static libraries — set of functions to be incorporated into executable. Unlike object files, they must contain all dependencies. Extension .a innix and *.lib in Windows.
- Dynamic libraries — a special type of library which is suitable to be loaded once for many programs at the same time. In such case, no their code is incorporated into binary but only references to them. Such code doesn’t have to be duplicated in RAM too. However, each process has separate space for data. Unlike static libraries, they have also initialization code that is run when the library is loaded. They may be loaded at the same time as whole binary or during runtime using the system call. The second option is often used to deploy plugins. However this approach is convenient, it may cause problems with dependencies because of many versions of the same library. That’s why many (especially closed source) are distributed with libraries incorporated into the binary (ie. statically linked). Extension .so in Linux,.dll in Windows, .dylib inBSD (including Mac). In *nix systems they are usually stored in /lib /usr/lib (this can be reconfigured per system or per binary). Windows usually store them in Windows and Windows\System32 directory, but the directory with binary is checked by default.
- Executables — binaries intended to be run as standalone programs. They usually accept command line parameters and environment variables as an input. In *nix system they usually have no extension, in Windows *.exe.
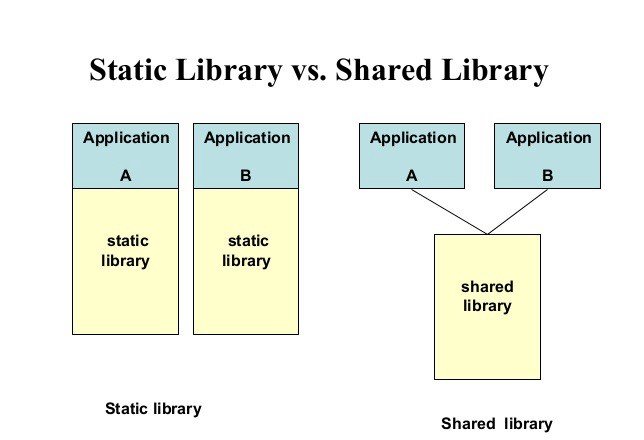 graphics from
here
graphics from
here
Very often, for RELEASE builds debug symbols are built in a separate file (*.debug). If you load it you can debug your program as though it had debug symbols. You can also disassemble it and examine as normal binary. Another use case for them is remote debugging. When you enable GDB server in QEMU or expose one from the embedded device (e.g. via serial port) you must have a local copy of the debugged code.
In modern PC platforms, we have 2 most common executable formats: PE (Windows, UEFI) and ELF (nix, coreboot). Raw executable code still can be found in legacy BIOS boot records (MBR). PE and ELF are different but share most important concepts. For instance, they both divide contents into sections. Generally, both formats can be examined in a very similar way (but tools differ a little bit). Among others, PE files can be examined using pev package (available also fornix systems), for ELF objdump from binutils is probably the most popular choice. In Reverse Engineering IDA is kind of the standard, but it’s much more complex solution.
Binary examination
Usually, we start by examining how binary is organized, that is sections and entry point (for executables). As this is very similar for both formats, so I’ll focus on ELF.
Executable may have only one section with code (usually called .text), but it’s rare that there are no .data (initialized data section), .rodata (initialized read-only data) or .bss (zero-initialized data). Still, such a minimalistic layout is typical for programs coded in assembly language. GCC usually create about 20 of them, however the most interesting for us would be .plt or .got which contains references to dynamically linked libraries. Typical C program loads at least standard library this way.
We can find entry point using:
|
|
The start address is so-called RVA — Relative Virtual Address, so it’s offset from the place in memory, where binary would be placed. To list sections we can call:
|
|
The most important for us is of course name, VMA (base address), size and offset in the file. LMA is rarely different than VMA so usually not relevant. As we see, names are arbitrary and the flags are defining section features, but it’s rather relevant in security analysis. In most cases, initialized data sections are the most interesting to us here, so that we can translate pre-initialized data RVA to the location in the file so that we can peek in (e.g. using hexdump). That’s because for each address based instruction some meaningful name would be printed (usually label + offset, for calls to dynamic libraries the name of call and library name). Note that all addresses here are noted in hexadecimal.
Calling objdump -d will print disassembly of whole binary So it’s better to
limit output. You may use --start-address=offset parameter or less and start
from looking for function name (function labels are usually included even in
RELEASE binaries). For debug binaries, you may consider -s option to mix
disassembly with source code.
|
|
As you see we have complete disassembly with RVA and hex representation of machine code for each instruction. As you see, most addresses are relative to RSP or RIP, but as the second one is given, there is also RVA and label given.
Note that if you prefer Intel syntax it can be changed, just as in pev you can switch from default Intel to AT&T.
Initial state
The last thing we must be aware of is the initial state of the process and this is platform dependent, but surely some details are common. Most likely we get fully initialized address space with all dynamically linked libraries already loaded (except those loaded in the code of course), RSP in the right location, etc. Command parameters are likely to be placed on the stack, however, it’s arrangement may differ.
For example in 64-bit Linux RSP would initially point at parameters count, and
then 8 bytes pointer to each argument starting from an executable name. This may
be little confusing as it’s not what you see in main() function which conforms
to C’s parameter format. The trick is that main() is not the entry point even
if it seems so when you run gcc -S. The entry point is usually referred as
_start and for C program it is automatically added in linking process. _start
calls special libc call which loads main from given address.
This is a typical _start function. It looks the same for C programs.
|
|
Further steps
That’s all you need to know in the beginning. As you see it’s not complex at all. The problem here is the amount of code to get through, but each instruction itself is not complex. Provided interface separate us from most of CPU and OS magic. Of course, interface of presented tools are not very good for more sophisticated analysis, but its output is very regular so it’s easy to transform it so that your favourite language can understand it and process.
Meaning of most instructions is trivial. We can consider library calls as the points where the program communicate with outside world. So we can decide, which of those points seem relevant to us so that we eliminate information noise.
